Lessons from the Cloudflare Outage: Building Resilient Cloud Architectures


On November 18 2025, Cloudflare, a major content-delivery and internet-infrastructure provider handling roughly 1 in 5 web requests globally, experienced a large-scale network failure[1]. The result: dozens of high-profile services such as ChatGPT, X (formerly Twitter), and other applications were rendered partially or fully unavailable for hours[2].
While the outage ultimately stemmed from a configuration error in Cloudflare’s internal bot-management feature file (not a malicious attack) it exposed how even the most robust infrastructure is vulnerable[3].
For organisations engaged in cloud-transformation, software delivery and landing-zone architecture (such as our work at ZEN), this is a wake-up call. How do you build systems that remain resilient when your provider — or a critical part of their stack — fails?
In this article, we cover the lessons we’ve distilled from the incident, and talk through how you can apply them when designing or revisiting your cloud architecture.
The Incident at a Glance
Around 11:20 UTC, Cloudflare detected a spike in “unusual traffic” to its network. The root cause turned out to be an unexpected expansion of a feature file tied to its Bot Management service. The file’s size exceeded limits, causing proxy systems to crash and trigger cascading 5xx errors across the network.
The outage affected core services, including Workers KV, Access, and the dashboard. The entire failure timeline lasted several hours — most traffic was restored by 14:30 UTC and full recovery by 17:06 UTC.
Key takeaways: this was not a DDoS attack; it was an internal configuration change that propagated globally and took down major infrastructure — showing how provider failures can ripple through your stack.
Lesson 1: Don’t Assume “Zero-Fail” from a Single Provider
Outages of this magnitude underline a simple fact: even widely distributed edge/CDN providers can fail in non-obvious ways. If your architecture assumes “Cloudflare (or provider X) = always on”, then you’re exposed.
Implication for architecting resilience:
-
Design for provider failure: Assume the edge provider will fail; plan how your traffic will route or degrade gracefully.
-
Avoid single-point provider coupling: Edge/CDN might be highly available — but what about control-plane services (e.g., WAF, access, bots, proxies)?
-
Fallback strategies matter: If your stack is tightly coupled to one provider feature-set, you need a robust fallback or degrade mode.
Lesson 2: Visibility & Recovery Paths Must Be Validated
The Cloudflare report reveals the difficulty of diagnosing cascading failures when the root cause is buried in configuration logic.
For your systems:
-
Monitor provider dependencies: Know which services you rely on (e.g., bot-management, edge proxy, KV, auth) and how failures propagate.
-
Define clear recovery paths: When provider component X fails, what fallback or bypass kicks in? In the Cloudflare case, bypassing the proxy for Workers KV reduced impact.
-
Test failover drills: Simulating provider-service failure improves readiness — not just app-server outages, but infrastructure/edge/CDN disruptions.
Lesson 3: Architecture for Partial Degradation, Not Just Full-Outage
Many systems aim only for “fully up” or “down”. The Cloudflare outage shows services may be degraded (higher latency, 500 errors) yet still partially operational. 4
Architect your systems to degrade gracefully:
-
Region fallback: If 1 region or provider zone suffers, traffic flows to another region/provider.
-
Feature toggles & graceful degradation: If advanced edge features (bots, WAF) fail, allow user traffic with reduced functionality rather than total outage.
-
Communication to users: For SaaS/apps, communicate degraded mode transparently rather than a sudden blackout.
Lesson 4: Multi-Provider and Multi-Layer Resilience
When building your cloud landing zone or application architecture, consider layering resilience across providers and services:
-
Use more than one CDN/edge provider (or at least multiple POPs or zones).
-
Separate your control plane from data plane — e.g., independent authentication or WAF services.
-
Version and test your provider-specific logic (e.g., bot-management rules or feature files) in production-like conditions.
This aligns with ZEN’s “Cloud Landing Zone” principle of building a well-architected foundation where dependencies are clear, resilience is baked in, and operations assume failure.
Lesson 5: Change-Management for Edge/Provider Configurations
Often, we treat application deployments as the risky phase — yet provider configuration changes, permission modifications or feature rollouts (as in Cloudflare’s case) can be root causes of large outages.
Your process should include:
-
Controlled roll-outs of provider configuration changes (canary, ring-deployment, staged).
-
Automated validation of changes (e.g., file limits, feature-file size, response volatilities).
-
Visibility into provider configuration state and change history.
Actionable Checklist for Engineering Teams
Here’s a practical checklist you can review this week:
-
Map all your external infrastructure dependencies (CDN, WAF, bot-management, edge proxies).
-
For each dependency, ask: “If this fails, how does traffic degrade?”
-
Perform a simulated failure drill of one dependency (e.g., disable bot module) outside business hours — review impact.
-
Build or test a fallback path or alternate provider.
-
Integrate change-management controls for provider-config changes (especially those for edge/security features).
-
Include the outcome of edge/provider failures in your cloud-landing-zone documentation and responsibilities.
The Cloudflare outage is more than a headline — it’s a clear reminder that even “global” providers can fail in deep and complex ways. For organisations transforming to cloud-native, adopting microservices, or building high-availability SaaS, resilience must include the often-hidden layers: edge infrastructure, CDN, bot-management, and provider control planes.
At ZEN, our view is simple: high-availability doesn’t mean “always up” — it means “always ready for failure." Build with the assumption that your edge provider will fail, validate your alternatives regularly, and ensure your landing zone can absorb the shock.
Because in architecture, how you handle failure often defines how you succeed.

Go Cloud Native, Go Big
Revolutionise your organisation by becoming a born-again cloud enterprise. Embrace the cloud and lead the future!
Read more:

How to Plan a Cloud Migration (Without Losing Your Mind)
You know you need to move to the cloud. But you're terrified: What if we lose data? How long will this take? What if it ...
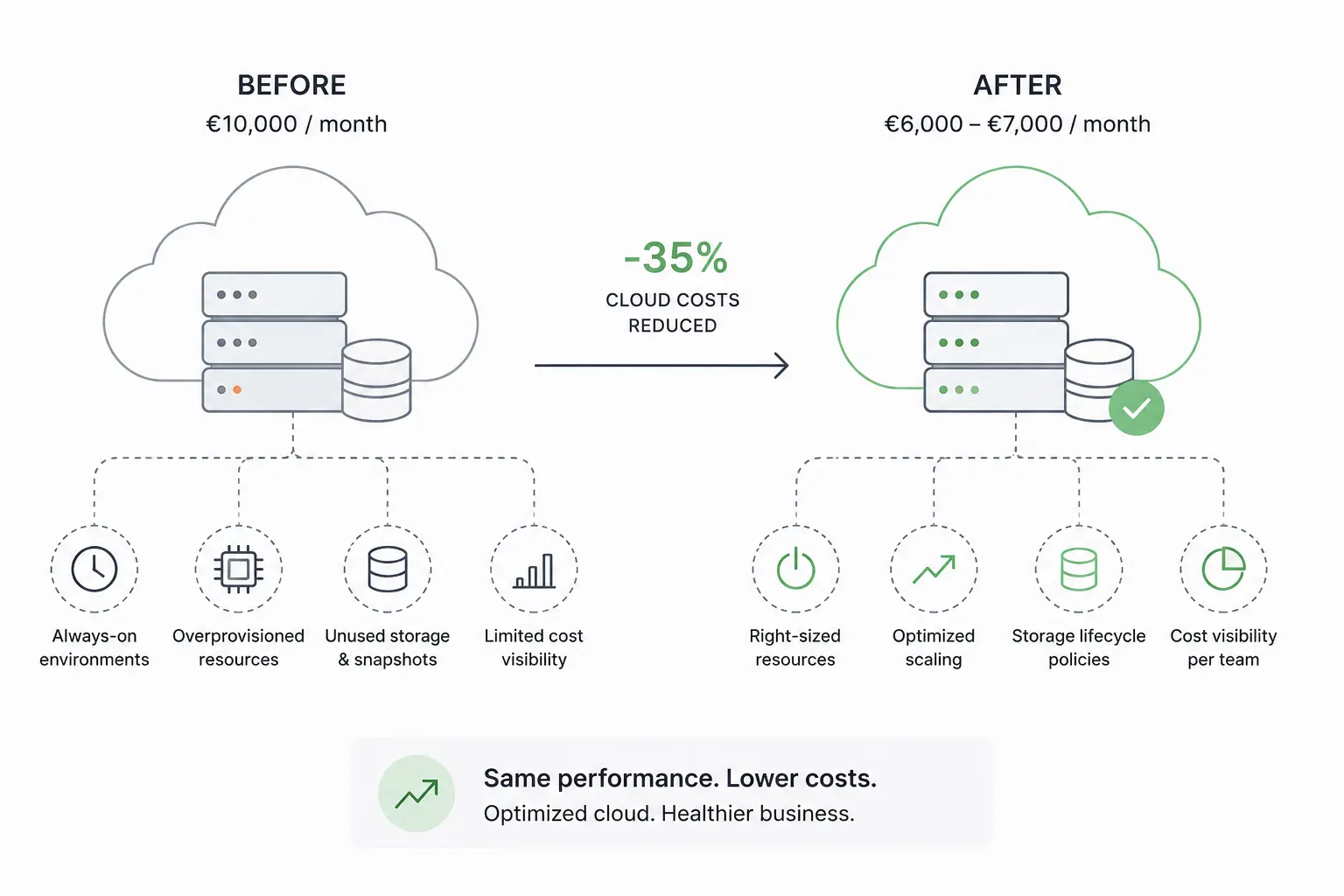
Cloud Cost Optimisation: How We Helped a SaaS Company Reduce Cloud Spend by 35%
A small SaaS company with around 50 employees approached us with a concern that had begun to surface in budget discussio...

Cloud Observability vs. Cloud Monitoring
The difference between monitoring and observability only really shows up when something goes wrong, and the usual tools ...

What Happens When a Cloud Region Goes Down
Most teams build their systems expecting small failures. A container crashes. A node disappears. Maybe an availab...

Cloud Security Basics Developers Often Ignore
Cloud security is often framed as a shared responsibility. In practice, that usually translates to something like: “the ...

Why Most Cloud Migrations Fail Before the First Deployment
Cloud migration often starts with confidence. The plan sounds simple: move existing systems to the cloud, reduce infrast...