Disaster Recovery in the Age of Remote Work


The way we work has changed dramatically. Remote and hybrid models have shifted software development and IT operations from centralised offices to globally distributed teams. While this brings flexibility and broader talent pools, it also introduces new challenges for disaster recovery (DR). Traditional DR strategies assumed co-located teams, centralised data, and on-premises infrastructure. Today, companies need strategies that support remote-first operations, ensure business continuity, and protect critical data across multiple locations and cloud environments.
This article explores practical approaches to disaster recovery in the age of remote work, common pitfalls, and actionable recommendations for modern teams.
Rethinking Disaster Recovery for Distributed Teams
In the past, disaster recovery focused on physical disasters: fires, flooding, or on-premises server failure. Today, potential disruptions include cloud provider outages, cyberattacks targeting remote endpoints, network failures, and data corruption across multiple cloud regions. For distributed teams, DR planning must account not only for technology but also for people and processes spread across different locations.
Remote employees need seamless access to DR procedures, and communication channels must remain redundant and reliable. Testing DR scenarios also requires coordination across time zones to ensure real-world readiness.
Modern Disaster Recovery Approaches
Cloud-first strategies have become essential. Multi-region deployments allow services to remain available even if one region experiences downtime. Automated backups ensure data is securely replicated across multiple locations, while infrastructure as code (IaC) tools like Terraform or CloudFormation enable rapid environment rebuilds when disasters strike.
Disaster recovery now also encompasses the protection of employee devices and collaborative tools. Laptops, desktops, and local development environments should have encrypted backups, while versioned backups for shared drives, Git repositories, and collaboration tools are crucial. Geo-redundant cloud storage ensures that a single regional failure does not result in catastrophic data loss.
Communication and coordination are equally important. Distributed teams must maintain clear contact lists and escalation paths, use asynchronous tools for alerts and instructions, and participate in periodic DR drills to validate readiness.
Testing and Continuous Improvement
Testing DR procedures is critical. Simulations should mimic real-world disruptions without affecting production, including scenarios involving home networks, VPN latency, or cloud service failures. After each drill, teams should evaluate recovery time objectives (RTO) and recovery point objectives (RPO) to identify bottlenecks in remote access or coordination. Plans must be continuously updated to reflect lessons learned and improve future readiness.
Security Considerations
Remote work introduces additional security challenges. All data, whether in transit or at rest, must be encrypted, including backups stored on employee devices. Role-based access control ensures that only authorised personnel can access DR systems. Multi-factor authentication and monitoring for unusual activity are critical for protecting cloud accounts. Finally, incident response procedures should be integrated into DR plans to address cyberattacks such as ransomware, which can impact distributed environments.
Automation: Your Remote DR Ally
Automation reduces human error and accelerates recovery. Infrastructure as code templates allow teams to spin up systems quickly, automated failover ensures continuous availability, and backup validation scripts confirm that stored data is complete and usable. Automation allows distributed teams to perform DR tasks without being co-located, improving resilience and operational efficiency.
Key Metrics to Track
Monitoring the effectiveness of your DR strategy is essential. Distributed teams should pay attention to these metrics:
-
Recovery Time Objective (RTO): RTO measures the time required to restore services after a disaster. A lower RTO means faster recovery and less downtime, which is critical for remote-first teams where delays can disrupt global workflows.
-
Recovery Point Objective (RPO): RPO defines the maximum amount of data loss acceptable in case of a disaster. It guides backup frequency and ensures that critical data is not lost across distributed systems.
-
Backup Success Rate: This metric tracks the percentage of successful backups that are verified for integrity. Regular testing ensures backups are reliable and can be restored when needed.
-
Failover Drill Completion Time: Measuring how long it takes to complete a simulated failover helps identify bottlenecks in processes, tools, or remote coordination.
-
Employee DR Awareness: A key human metric — it reflects the percentage of team members who can follow DR procedures correctly. Awareness and training are vital for remote teams where instant guidance may not be available.
Cultural and Organisational Considerations
Disaster recovery is not purely technical. Teams must be trained on procedures, and DR responsibilities should be part of onboarding new employees. Organisations that encourage reporting issues and testing DR scenarios foster a culture of preparedness. Documentation should be accessible, clearly structured, and kept up-to-date, so all team members, regardless of location, can follow procedures efficiently.
Conclusion
Disaster recovery in the era of remote work requires rethinking traditional assumptions. Organisations must embrace cloud-first strategies, secure remote endpoints, maintain reliable communication, and commit to continuous testing. A strong DR plan protects infrastructure, people, and processes alike. Remote-first teams that implement these strategies gain confidence, agility, and resilience — turning disaster recovery from a reactive safety net into a strategic advantage.

Go Cloud Native, Go Big
Revolutionise your organisation by becoming a born-again cloud enterprise. Embrace the cloud and lead the future!
Read more:

How to Plan a Cloud Migration (Without Losing Your Mind)
You know you need to move to the cloud. But you're terrified: What if we lose data? How long will this take? What if it ...
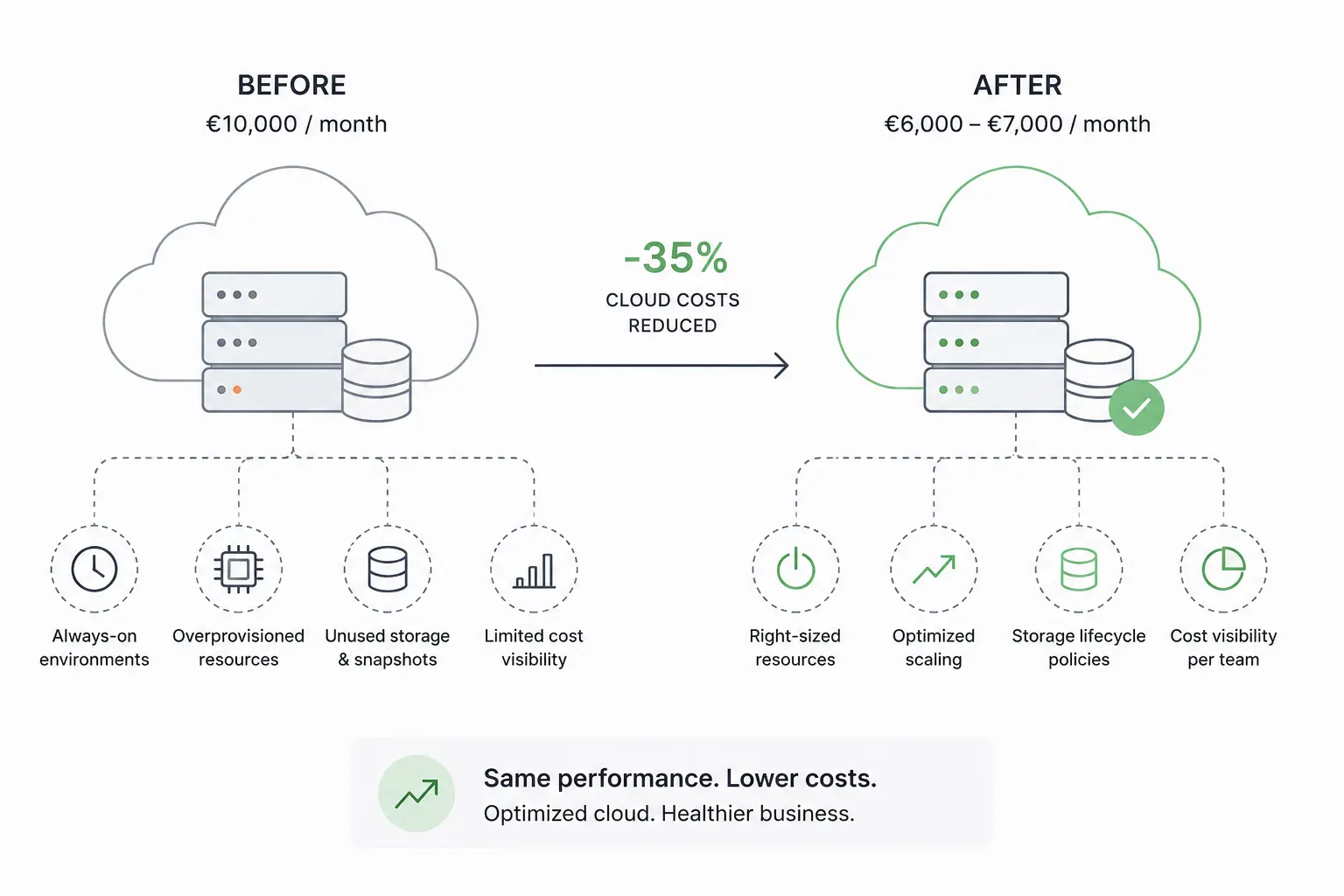
Cloud Cost Optimisation: How We Helped a SaaS Company Reduce Cloud Spend by 35%
A small SaaS company with around 50 employees approached us with a concern that had begun to surface in budget discussio...

Cloud Observability vs. Cloud Monitoring
The difference between monitoring and observability only really shows up when something goes wrong, and the usual tools ...

What Happens When a Cloud Region Goes Down
Most teams build their systems expecting small failures. A container crashes. A node disappears. Maybe an availab...

Cloud Security Basics Developers Often Ignore
Cloud security is often framed as a shared responsibility. In practice, that usually translates to something like: “the ...

Why Most Cloud Migrations Fail Before the First Deployment
Cloud migration often starts with confidence. The plan sounds simple: move existing systems to the cloud, reduce infrast...