Best Practices for Cloud Backup and Disaster Recovery in a Remote-First World


The rise of remote-first work has changed how businesses think about resilience. Employees now access systems from homes, coworking spaces, and across time zones. Company data is spread across SaaS platforms (Microsoft 365, Slack, Google Workspace), cloud infrastructure (AWS, Azure, GCP), and hybrid setups.
In this environment, cloud backup and disaster recovery (DR) have gone from being “just IT’s responsibility” to a core business requirement. Downtime no longer just means IT is stuck — it means an entire global team can’t work, customers lose access, and revenue disappears.
This article breaks down best practices for cloud backup and disaster recovery in a remote-first world — with a practical focus on what actually works, tools you can use, and the trade-offs to consider.
Backup vs. Disaster Recovery: What’s the Difference?
Before diving into practices, it’s important to clear up a common misunderstanding.
Backup = Creating and storing copies of data so you can restore it if it’s deleted, corrupted, or encrypted by ransomware. Example: Restoring an accidentally deleted Slack channel or rolling back a corrupted database table.
Disaster Recovery (DR) = The broader process of restoring systems, infrastructure, and operations after a major disruption (power outage, ransomware attack, region-wide cloud failure). Example: A data centre outage in Virginia takes down your main AWS region, so you fail over to a backup region in Frankfurt.
Think of backup as the foundation (your data is safe), and DR as the whole house (your business keeps running). You need both.
Best Practices for Cloud Backup
1. Follow the 3-2-1-1 Rule
The traditional 3-2-1 rule (3 copies, 2 media, 1 offsite) has evolved to deal with modern ransomware and cloud risks:
-
3 copies of your data (production + 2 backups)
-
2 types of storage (local + cloud, or cloud + tape)
-
1 offsite copy (secondary cloud region or third-party provider)
-
1 immutable copy (protected from edits/deletion — critical against ransomware)
👉 Example:
-
Production data in AWS (Virginia).
-
Backup copy in AWS S3 (California).
-
Immutable copy in Wasabi or Backblaze with Object Lock enabled.
2. Automate and Schedule Backups
Remote-first companies can’t rely on manual backups. They need automated schedules with:
-
Versioning (multiple restore points in case one backup is corrupted).
-
Application-aware backups (databases flushed properly before snapshot).
-
Notifications if a backup fails.
👉 Tools:
-
AWS Backup, Azure Backup, Veeam, or Rubrik for cloud workloads.
-
Databases: native tools like
pg_dump(Postgres),mongodump(MongoDB), automated via cron or cloud functions.
3. Don’t Forget SaaS Backups
Biggest misconception: “Microsoft/Google/Slack automatically back everything up.” Reality: They provide uptime guarantees, not long-term recovery.
-
Microsoft 365 only retains deleted files for 30 days (default).
-
Google Workspace has limited retention for Drive and Gmail.
-
Slack free tier doesn’t even retain messages past 90 days.
👉 Best practice: Use third-party SaaS backup providers (e.g., Druva, SpinBackup, OwnBackup, Datto) to get reliable restore options for SaaS tools.
4. Encrypt Data Everywhere
Remote-first work = more endpoints = more risk. Backup data must be secure at every step:
-
At Rest: Use AES-256 encryption for stored backups.
-
In Transit: TLS/SSL for transfers.
-
Access Control: Role-based permissions + MFA on backup consoles.
-
Separation of Duties: The person who configures backups shouldn’t be the same one who can delete them.
👉 Example: Configure AWS S3 backups with KMS encryption + bucket policies that prevent deletion unless approved by two roles.
5. Test Restores, Not Just Backups
A backup that hasn’t been tested might as well not exist. Remote-first companies need confidence that files, VMs, and SaaS data can actually be restored.
👉 Best practices:
-
Test file-level restores monthly (e.g., restore a deleted file).
-
Test application restores quarterly (e.g., recover a test database).
-
Simulate full failovers annually (e.g., spin up workloads from scratch in a secondary region).
-
Document results and refine the process after each test.
Best Practices for Disaster Recovery
1. Define RTO and RPO Clearly
Two metrics drive every DR strategy:
-
Recovery Time Objective (RTO): How quickly must you restore? (Minutes, hours, days).
-
Recovery Point Objective (RPO): How much data can you afford to lose? (Last 5 mins vs. last 24 hrs).
👉 Example:
-
Customer-facing API → RTO: 15 min, RPO: 5 min.
-
HR portal → RTO: 24 hrs, RPO: 12 hrs.
Without defining these, you’ll either overspend on DR or leave critical systems exposed.
2. Use Multi-Region and Multi-Cloud
-
Multi-Region: Run workloads in multiple regions of the same cloud provider.
Example: AWS Virginia (primary) + AWS Oregon (failover). -
Multi-Cloud: For ultra-critical workloads, replicate across providers. Example: Primary in AWS, secondary in Azure.
Pros: More resilience. Cons: Higher costs, more complexity.
3. Classify and Prioritise Workloads
Not every system deserves the same DR investment. Use tiering:
-
Tier 1: Mission-critical (e-commerce platform, customer APIs) → hot standby, active-active replication.
-
Tier 2: Important (internal dashboards) → warm standby, hourly backups.
-
Tier 3: Non-essential (archival data) → cold storage, restore on demand.
👉 This avoids wasting resources on non-essential workloads.
4. Leverage Infrastructure as Code (IaC)
Rebuilding environments by hand during a disaster is slow and error-prone. With IaC tools, you can redeploy an entire stack in minutes.
👉 Tools:
-
Terraform, Pulumi, AWS CloudFormation.
-
GitOps with ArgoCD for Kubernetes clusters.
Best practice: Store DR runbooks + IaC templates in version-controlled repos.
5. Run Regular DR Drills
Even the best DR plans fail if nobody knows how to execute them. Run:
-
Tabletop exercises quarterly (walk through disaster scenarios).
-
Technical failovers occur annually (actually fail over workloads).
👉 Example: Simulate a ransomware attack by disabling the primary environment and recovering from immutable backups in a test environment.
Challenges in a Remote-First World
1. Distributed Workforce
Employees may have poor home internet connections. Solution: Use VDI (Virtual Desktop Infrastructure) or browser-based apps that can be spun up quickly in a failover environment.
2. Ransomware Everywhere
Remote-first = more phishing = more ransomware. Mitigation: Immutable backups, zero-trust principles, and least-privilege IAM policies.
3. Compliance Pressure
Regulations like GDPR, HIPAA, and CSRD require documented recovery processes. Solution: Automate audit logs, monitoring, and compliance reporting with cloud-native tools.
Putting It All Together
In a remote-first world, backup keeps your data safe and disaster recovery keeps your business running. You can’t treat them separately.
To recap:
-
Adopt the 3-2-1-1 rule.
-
Automate SaaS + cloud backups.
-
Encrypt and secure access.
-
Define RTO/RPO for every workload.
-
Use multi-region, multi-cloud, and IaC for resilience.
-
Test restores and run DR drills regularly.
A strong backup and DR plan doesn’t just save IT headaches — it ensures your remote-first workforce can stay productive, your customers stay online, and your brand stays trusted.

Go Cloud Native, Go Big
Revolutionise your organisation by becoming a born-again cloud enterprise. Embrace the cloud and lead the future!
Read more:

How to Plan a Cloud Migration (Without Losing Your Mind)
You know you need to move to the cloud. But you're terrified: What if we lose data? How long will this take? What if it ...
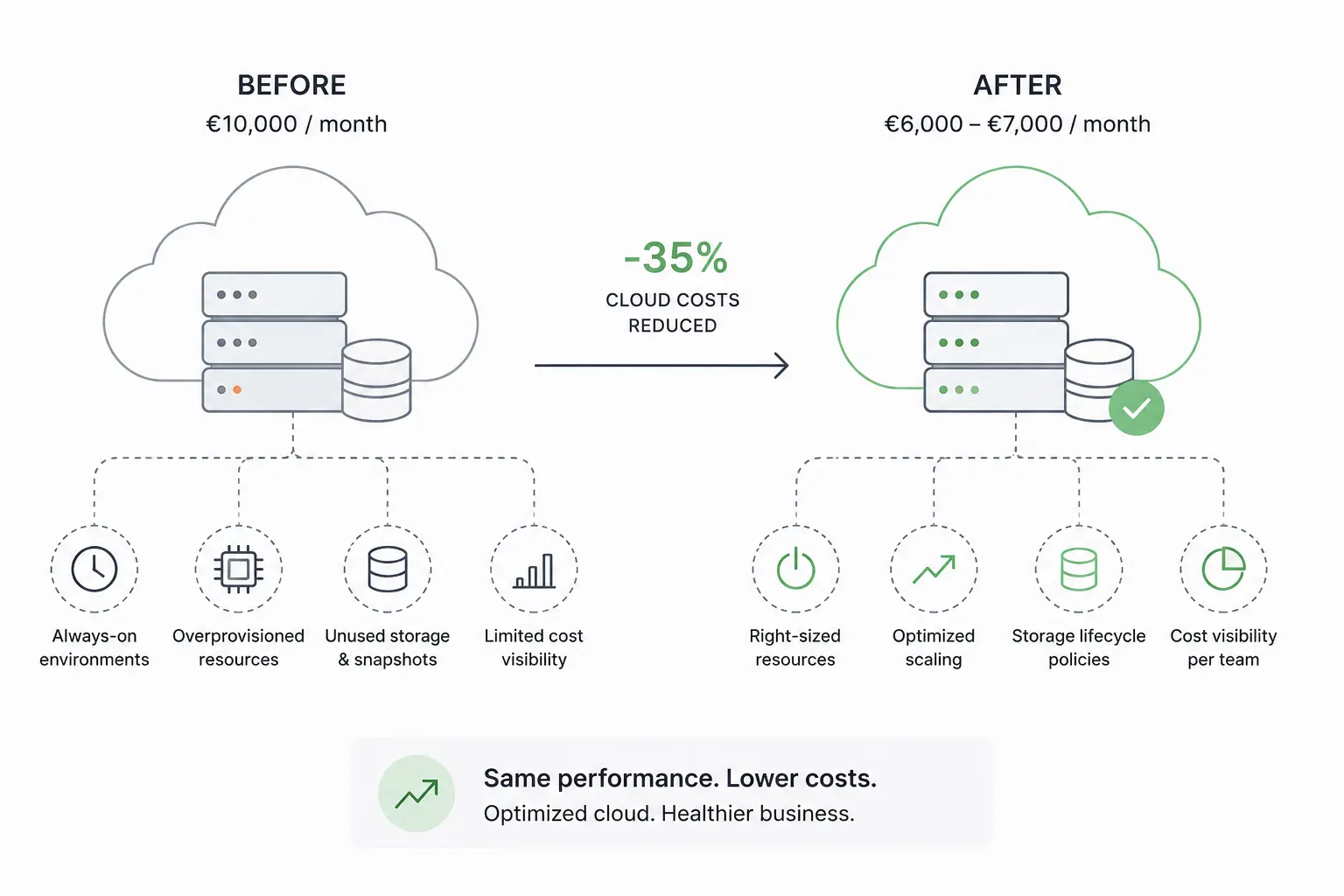
Cloud Cost Optimisation: How We Helped a SaaS Company Reduce Cloud Spend by 35%
A small SaaS company with around 50 employees approached us with a concern that had begun to surface in budget discussio...

Cloud Observability vs. Cloud Monitoring
The difference between monitoring and observability only really shows up when something goes wrong, and the usual tools ...

What Happens When a Cloud Region Goes Down
Most teams build their systems expecting small failures. A container crashes. A node disappears. Maybe an availab...

Cloud Security Basics Developers Often Ignore
Cloud security is often framed as a shared responsibility. In practice, that usually translates to something like: “the ...

Why Most Cloud Migrations Fail Before the First Deployment
Cloud migration often starts with confidence. The plan sounds simple: move existing systems to the cloud, reduce infrast...